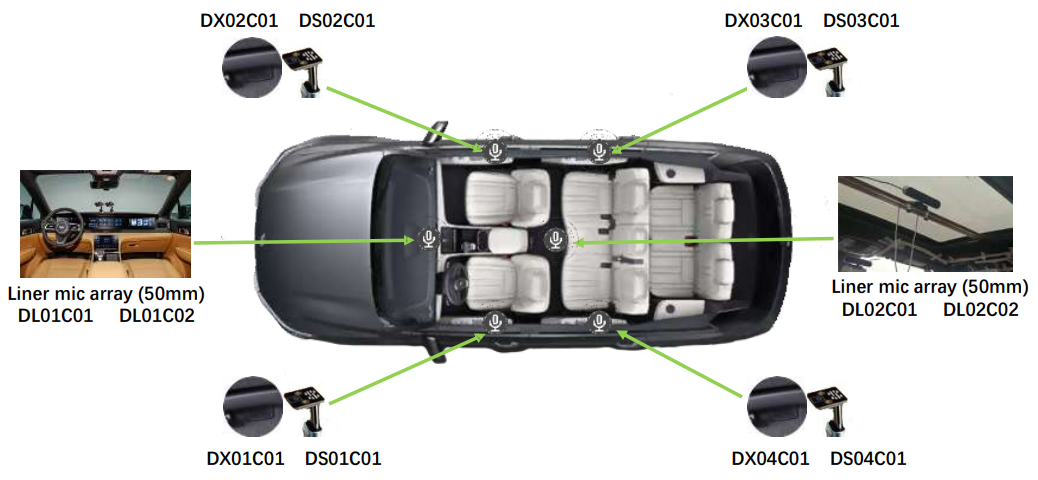
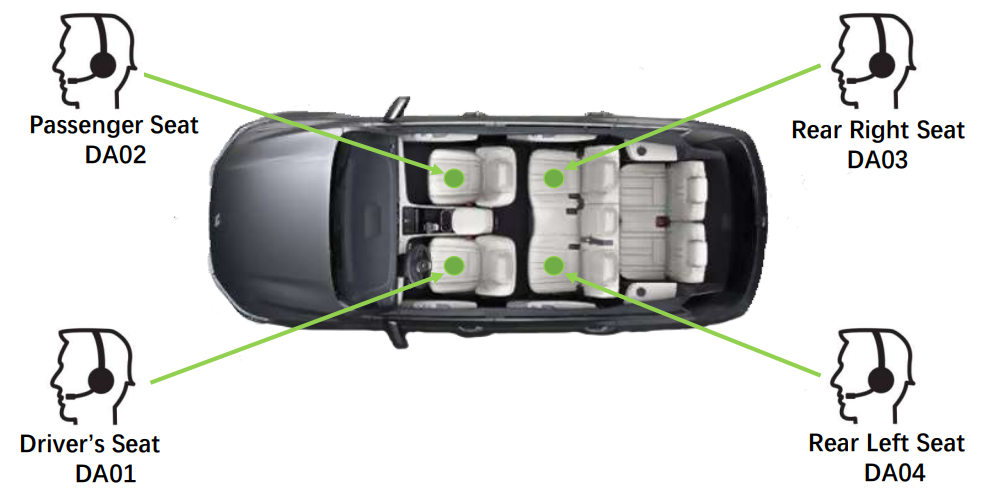
Track Setting and Evaluation
The ICMC-ASR challenge comprises two distinct tracks:
- Track I Automatic Speech Recognition (ASR): In this track, participants will be provided with the oracle segmentation of the evaluation set. The primary objective of this track is to focus on the development of ASR systems based on the multi-channel multi-speaker speech data. Participants need to devise algorithms that can effectively fuse information across different channels, suppress inevitable background noise, handle multi-speaker overlaps, etc.
- Track II Automatic Speech Diarization and Recognition (ASDR): Unlike Track I, Track II does not provide any prior or oracle information during evaluation (e.g. segmentation and speaker label for each utterance, total number of speakers in each session, etc.). Participants in this task are required to design automatic systems for both speaker diarization (identifying who is speaking when), and transcription (converting speech to text). Both pipeline and end-to-end systems are acceptable in this track, allowing for flexibility in system design and implementation.
It is important to note that, to ensure the authenticity of the results submitted by participants in the ASDR track, two distinct evaluation sets will be prepared for the two tracks.
For Track I, the accuracy of ASR system is measured by Character Error Rate (CER). The CER indicates the percentage of characters that are incorrectly predicted. Given a hypothesis output, it calculates the minimum number of insertions (Ins), substitutions (Subs), and deletions (Del) of characters that are required to obtain the reference transcript.
For Track II, we adopt concatenated minimum permutation character error rate (cpCER) as the metric for ASDR systems. The calculation of cpCER involves three steps. First, concatenate recognition results and reference transcriptions belonging to the same speaker along the timeline within a session. Second, calculate the CER for all permutations of speakers. Last, select the lowest CER as the cpCER for that session.

Figure 1: The Li Auto and microphones for data collections